- Is there something like MSVC's __assume with gcc? - 2 Updates
- hash<size_t> - 7 Updates
- overloading static operator + (non member) with non-class native types ... - 6 Updates
| Manfred <noname@add.invalid>: Sep 22 05:20PM +0200 On 9/18/2019 12:04 PM, David Brown wrote: > } \ > if (!(x)) __builtin_unreachable(); \ > } while (0) I am not an expert in gcc builtins, so I may be wrong, however it looks like there might be a small risk in that it suffers from the common problem with macros, i.e. 'x' is evaluated a number of times. The risk is small because obviously this kind of expression is not meant to have side effects on the argument, but still.. |
| David Brown <david.brown@hesbynett.no>: Sep 22 08:32PM +0200 On 22/09/2019 17:20, Manfred wrote: > I am not an expert in gcc builtins, so I may be wrong, however it looks > like there might be a small risk in that it suffers from the common > problem with macros, i.e. 'x' is evaluated a number of times. My understanding (through tests and a rough understanding of what the builtin does, but not through documentation in the manual) is that __builtin_constant_p() does not evaluate the expression. If it is true, then it doesn't matter that "x" is evaluated several times - after all, it is a compile-time constant. So "x" is only evaluated once in cases where it may matter. > The risk is small because obviously this kind of expression is not meant > to have side effects on the argument, but still.. Agreed. It is always important to consider whether there are multiple evaluations in a macro, and whether it is relevant. Although it does not matter in this case, in general it is a good idea to write something like this: #define assume(x) \ do { \ const auto xx = x; \ if (__builtin_constant_p(xx)) { \ if (!(xx)) { \ assumeFailed(); \ } \ } \ if (!(xx)) __builtin_unreachable(); \ } while (0) For C, use "const __auto_type xx = x;" - it's a gcc extension, but so are the builtins. |
| Melzzzzz <Melzzzzz@zzzzz.com>: Sep 22 02:53AM > randomness with a significantly smaller amount of buckets than the > maximum key value, and will usually cause an enormous amounts of > collisions. How so? It depends on value itself. You can map value to index which is smaller simply as value % buckets > they do this because of pure laziness (or to avoid some kind of > controversy, as there is no universally agreed "best" hashing > function for integers). Mapping value to buckets is performed anyway, but using same value has advantage of zero collisions in hash value, what is better? -- press any key to continue or any other to quit... U ničemu ja ne uživam kao u svom statusu INVALIDA -- Zli Zec Na divljem zapadu i nije bilo tako puno nasilja, upravo zato jer su svi bili naoruzani. -- Mladen Gogala |
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 06:46AM +0200 >> function for integers). > Mapping value to buckets is performed anyway, but using same value > has advantage of zero collisions in hash value, what is better? There's one seemingly refutation: imagine you have a 1:1 hash-key of values 0 to 2 ^ 16 - 1 and you have 256 buckets; so you drop the upper byte of the hash-key to get the bucket-index. And imagine you have input-values which are a multiple of 256; in this case a 1:1 -mapping wouldn't be good as the keys were all mapped to the same bucket. So multiplying the input value with a prime would be better here. But the truth is: such a distribution of input-values is not common. |
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 02:40PM +0200 > with 1:1-mapping wont get any collisions. The whole issue is becoming more and more strange: I've just written a tiny function that uses std::hash<size_>t to return a hashed value of a input size_t. This is the code: #include <functional> using namespace std; size_t f123( size_t s ) { hash<size_t> hasher; return hasher( s ); } Now here's the MSVC-code with full optimizations: ?f123@@YA_K_K@Z PROC mov r8, rcx movzx r9d, cl mov r10, 1099511628211 ; 00000100000001b3H mov rax, -3750763034362895579 ; cbf29ce484222325H xor r9, rax mov rax, rcx shr rax, 8 movzx edx, al mov rax, rcx shr rax, 16 movzx ecx, al mov rax, r8 shr rax, 24 imul r9, r10 xor r9, rdx imul r9, r10 xor r9, rcx movzx ecx, al imul r9, r10 mov rax, r8 shr rax, 32 xor r9, rcx movzx ecx, al mov rax, r8 shr rax, 40 movzx eax, al imul r9, r10 xor r9, rcx mov rcx, r8 imul r9, r10 shr rcx, 48 xor rax, r9 movzx edx, cl imul rax, r10 shr r8, 56 xor rax, rdx imul rax, r10 xor rax, r8 imul rax, r10 ret ?f123@@YA_K_K@Z ENDP _What they're smoking in Redmond?_ Are they trying to get crypto-hashes from size_t? ;-) Actually output-value = input-value would be sufficient. If you don't want the repeated-bucket-problem described by me here in another article in this thread, multiplying with a prime would be ok, thereby discarding the bits not fitting in size_t. Here's an implementation of a multiplci- cation with the largest prime fitting in size_t on a 64-bit-machine (this is still suitable as long as the correspoding prime isn't a meresenne prime): #include <functional> using namespace std; size_t f123( size_t s ) { size_t const MAXPRIME64 = 0xffffffffffffffc5u; return s * MAXPRIME64; } This is the resulting code: ?f123@@YA_K_K@Z PROC imul rax, rcx, -59 ; ffffffffffffffc5H ret 0 ?f123@@YA_K_K@Z ENDP |
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 03:32PM +0200 > mov r10, 1099511628211 ; 00000100000001b3H > mov rax, -3750763034362895579 ; cbf29ce484222325H So, diese beiden Werte machten mich stutzig. Ich hab mal durch die STL-Implementation von MS gesucht und da gab es eine constexpr -"Variable", die war folgendermaßen definiert: constexpr size_t _FNV_offset_basis = 14695981039346656037ULL; Desweiteren war 0x00000100000001b3u, also deziaml 1099511628211, folgeend zu finden: size_t _FNV_prime = 1099511628211ULL; Dann habv ich mal nach "_FNV_offset_basis" gesucht unnd bin auf folgenden Wikipeida-Artikel gestoßen: https://bit.ly/2Pa3Owh Da ist der Algorithmus beschrieben als nicht-kryptografischer Hash-Algorithmus (kann ja prinzipiell bei 64 Bit Output schon mal gar nicht sein). Auf jeden Fall ist der für das was man so braucht recht aufwendig. |
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 03:49PM +0200 > Hash-Algorithmus (kann ja prinzipiell bei 64 Bit Output schon > mal gar nicht sein). Auf jeden Fall ist der für das was man > so braucht recht aufwendig. Sorry, the resonse should be directed to a german newsgroup. So here's the english translation: Both values made me curious. I've searched through MS' ST-implementation and there was a constexpr-"variable that was defined like this: constexpr size_t _FNV_offset_basis = 14695981039346656037ULL; Further there was 0x00000100000001b3u, i.e. 1099511628211 decimally, to find: size_t _FNV_prime = 1099511628211ULL; I googled for "_FNV_offset_basis" and found this Wikipedia-article: https://bit.ly/2Pa3Owh . The algorithm described there is a non-crypto- graphic hash-algorithm (coudln't be hardly ever with a 64-bit output). Anyway that's a rather expensive implementation. |
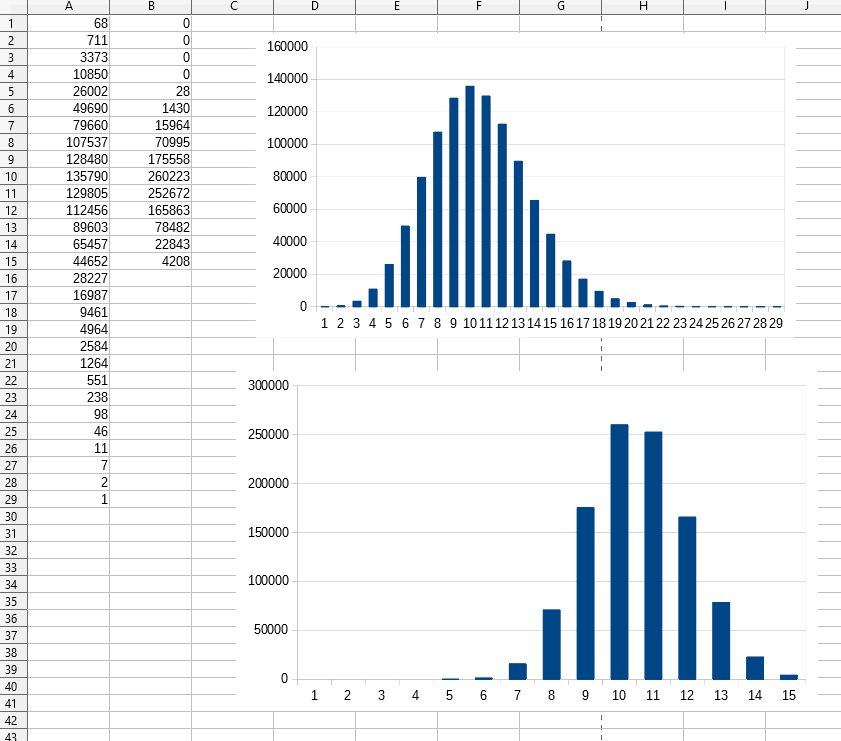
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 06:25PM +0200 I've analyzed the properties of the different hash-algorithms with the following program: #include <iostream> #include <cstddef> #include <random> #include <limits> #include <vector> #include <cmath> #include <functional> #include <algorithm> using namespace std; void showHashStatistics( vector<unsigned> &v ); int main() { size_t const MAX64_PRIME = 0xffffffffffffffc5u; size_t const N_BUCKETS = 0x100000; random_device rd; uniform_int_distribution<size_t> uidHash( 0, numeric_limits<size_t>::max() ); vector<unsigned> v; v.resize( N_BUCKETS, 0 ); cout << "simple prime hash:" << endl; for( size_t i = 0; i != 10'000'000; ++i ) ++v[(size_t)(uidHash( rd ) * MAX64_PRIME) % N_BUCKETS]; showHashStatistics( v ); cout << endl; cout << "hash<size_t>:" << endl; fill( v.begin(), v.end(), 0 ); hash<size_t> hasher; for( size_t i = 0; i != 10'000'000; ++i ) ++v[hasher( i ) % N_BUCKETS]; showHashStatistics( v ); } void showHashStatistics( vector<unsigned> &v ) { unsigned min = numeric_limits<unsigned>::max(); unsigned max = 0; for( unsigned x : v ) min = x < min ? x : min, max = x > max ? x : max; cout << "min: " << min << " max: " << max << endl; double avg = 0; for( unsigned x : v ) avg += x; avg /= v.size(); cout << "average: " << avg << endl; double rmsd = 0.0; double sq; for( unsigned x : v ) sq = (x - avg), rmsd += sq * sq; rmsd = sqrt( rmsd / v.size() ); cout << "standard deviation: " << rmsd << endl << endl; cout << "distrubution:" << endl; vector<unsigned> vDist; vDist.resize( max + 1, 0 ); for( unsigned x : v ) ++vDist[x]; for( unsigned i = 0; i < max; ++i ) cout << vDist[i] << endl; } It makes the following: it fills a vector with 2 ^ 20 (about one million) unsigneds with zeroes. Then it calculates 10 million hashes. Each hash is then taken modulo the vector-size and this is taken as an index to the vector and the according element is incremented. That's like not having any buckets but just to count the fill-degree of each bucket. Then I output different statistics: the maximum load, the minumum load, the average load and the standard deviationaround the average. For the trivial solution min is zero, max is 29, the average is 9,54 and the standard deviation is 3,09. For the MS hash<size_t>-solution min is 4, max is 15, the average is 9,54 (the program outputs some more digits and they're equal to the average of the simple solution!). The standard deviation is a bit smaller, 3,09 vs. 1,52 around an average of 9,54. And if something here thinks that's not a subject for standard deviations because we won't have any similar like a normal distribiotion, here't the proof: https://ibin.co/4vuLPDgTcwYY.png The above is the simple algorithm and the lower is that of MS. Because of the high number of distinct values one might think that the algorithm MS is significantly better, but this is isn't really true because the average is the same and the values don't vary much differently. So I don't know why MS makes such a high effort just because of such a little difference. And imagine that the time in 1,5 buckets more might be outweight by the simpler hashing-algo- rithm. And now something different: when I displayed the distribition with Openoffice, I was surprised that I almost got a standard distribution. This means that prime number arithmetics results in distrubition-properties which can be found in nature. But that's higher mathematics I won't understand in this life. |
| Bonita Montero <Bonita.Montero@gmail.com>: Sep 22 07:32PM +0200 > ++vDist[x]; > for( unsigned i = 0; i < max; ++i ) > cout << vDist[i] << endl; And I added some code after that here: double mean = (double)numeric_limits<size_t>::max() / 2.0; normal_distribution<double> nd( mean, sqrt( mean ) ); cout << endl; cout << "normal distribution:" << endl; fill( v.begin(), v.end(), 0 ); for( size_t i = 0; i != 10'000'000; ++i ) ++v[((size_t)nd( rd ) * MAX64_PRIME) % N_BUCKETS]; showHashStatistics( v ); This uses a normal distrubution around 2 ^ 63 - 1with a standard deviation of sqrt( 2 ^ 63 - 1 ) as the random input. This input is further multiplied with MAX64_PRIME and taken modulo the bucket -size. The distrubution is really strange: nearly all buckets fall on the first bucket index, i.e. excactly 2 ^ 20 - 1024! The is distributet on the remaining 1024 buckets. So theres not a relation- ship in the direction that the hash-calculations give a normal dis- tribution but also in the other direction, that the normal-distri- bution projected through a hash-algorithm results in almost only one bucket filled. WTF is going on there? Has anyone some mathee- matical explanation for that? |
{kind=link}
| Chris Vine <chris@cvine--nospam--.freeserve.co.uk>: Sep 22 12:28AM +0100 On Fri, 20 Sep 2019 21:52:04 +0300 > concatenating them) belong to another language which is supported for > legacy only. If you just avoid using char* strings and literals your > problem will disappear. However a std::string object cannot be constexpr because it has a non-trivial destructor, whereas a C string literal is constexpr. Subject to the small string optimization, std::string involves an allocation, so there are definitely cases where C string literals are a better choice (and cases where they are not). By contrast, std::string_view can be constexpr, where it references a C string literal. |
| Paavo Helde <myfirstname@osa.pri.ee>: Sep 22 11:30AM +0300 On 22.09.2019 2:28, Chris Vine wrote: > better choice (and cases where they are not). > By contrast, std::string_view can be constexpr, where it references > a C string literal. Right, I had forgotten about string_view (again...). So, for potentially best performance, one could use using namespace std::literals::string_view_literals; and "abc"sv (this is however a C++17 addition, so might not yet be available everywhere). "https://en.cppreference.com/w/cpp/string/basic_string_view/operator%22%22sv" |
| Soviet_Mario <SovietMario@CCCP.MIR>: Sep 22 01:38PM +0200 On 21/09/2019 18:08, Paavo Helde wrote: > std::string literal avoids one conversion involving one > strlen() call, at least conceptually, so my wild guess is it > should be as fast as or faster than using a char* literal. exactly my thought : i was suspecting a "template-like" resolution at compile time instead of calling a constructor at run-time. Using native const-literals could be resolved at least partially at compile time (no actual conversion at all). Unluckily, I did not discover whether and how to make QT creator free edition to support the standard 2014. It uses C++_X11 or sth similar. And don't recognize the "s" suffix (it complaints unexpected identifier after the literal). To be honest, I'm not sure that the problem is QT ide in itself or the compiler it relies upon (not brand new). Maybe upgrading the compiler version would convince the IDE to use the more recent standard ??? dunno. -- 1) Resistere, resistere, resistere. 2) Se tutti pagano le tasse, le tasse le pagano tutti Soviet_Mario - (aka Gatto_Vizzato) |
| Soviet_Mario <SovietMario@CCCP.MIR>: Sep 22 01:41PM +0200 On 21/09/2019 19:07, David Brown wrote: >> a compiler of its own in the free version) > AFAIK QT never ships with any compiler, no matter what > license you use. In fact it recognized the currently pre-installed version of GCC (both in Debian and in MX) > It is entirely up to /you/ which compiler > you use, and what settings you pick for it, including the > C++ standard to use. I just accepted the result of initial scan during QT installation, which recognized every installed compiler. -- 1) Resistere, resistere, resistere. 2) Se tutti pagano le tasse, le tasse le pagano tutti Soviet_Mario - (aka Gatto_Vizzato) |
| Paavo Helde <myfirstname@osa.pri.ee>: Sep 22 03:57PM +0300 On 22.09.2019 14:38, Soviet_Mario wrote: > edition to support the standard 2014. It uses C++_X11 or sth similar. > And don't recognize the "s" suffix (it complaints unexpected identifier > after the literal). If your compiler does not support std::string literals, you should have got an error already much earlier, at the "using namespace ..." line. |
| Soviet_Mario <SovietMario@CCCP.MIR>: Sep 22 03:02PM +0200 On 22/09/2019 14:57, Paavo Helde wrote: > If your compiler does not support std::string literals, you > should have got an error already much earlier, at the "using > namespace ..." line. yes ... and normally the intelligence opens a popup with acessible methods and members when it recognizes some valid header file added, this time it remained silent. -- 1) Resistere, resistere, resistere. 2) Se tutti pagano le tasse, le tasse le pagano tutti Soviet_Mario - (aka Gatto_Vizzato) |
| You received this digest because you're subscribed to updates for this group. You can change your settings on the group membership page. To unsubscribe from this group and stop receiving emails from it send an email to comp.lang.c+++unsubscribe@googlegroups.com. |
No comments:
Post a Comment